Speculative Decoding on Trainium Cuts LLM Inference Latency 3x
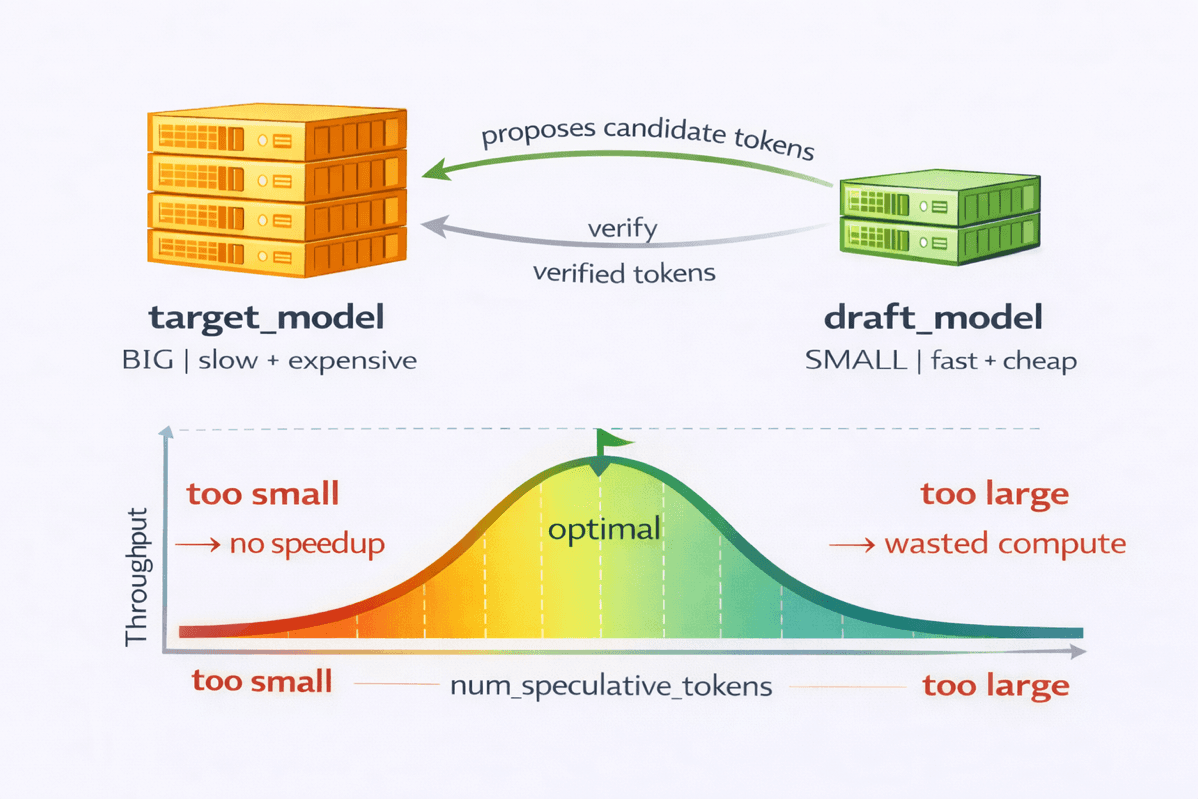
AWS and vLLM have demonstrated that speculative decoding on Trainium chips can accelerate token generation by up to 3x for decode-heavy LLM workloads. The technique uses a small draft model to propose multiple tokens at once, which a larger target model verifies in a single forward pass, reducing sequential decode steps and lowering per-token inference costs. The post provides benchmarks using Qwen3 models, practical tuning guidance for draft model selection and speculative token window sizing, and reproducible instructions for deployment on Kubernetes.
AWS and vLLM have demonstrated that speculative decoding on Trainium chips can accelerate token generation by up to 3x for decode-heavy LLM workloads. The technique uses a small draft model to propose multiple tokens at once, which a larger target model verifies in a single forward pass, reducing sequential decode steps and lowering per-token inference costs. The post provides benchmarks using Qwen3 models, practical tuning guidance for draft model selection and speculative token window sizing, and reproducible instructions for deployment on Kubernetes.
- Speculative decoding on AWS Trainium can reduce inter-token latency by up to 3x for decode-heavy inference workloads
- A draft model proposes multiple candidate tokens; the target model verifies them in one forward pass, reducing KV-cache memory round trips
- Key tuning parameters are draft model choice (must share tokenizer and vocabulary with target) and num_speculative_tokens window size
- Performance gains depend on token acceptance rates, which are highest when draft and target models share the same architecture
Decode-heavy workloads like AI writing assistants and coding agents spend most inference time on sequential token generation, making them memory-bandwidth-bound and expensive to run at scale. Speculative decoding directly addresses this bottleneck by parallelizing verification, which is a fundamental shift in how to optimize LLM inference cost. This technique is now production-ready on AWS hardware, making it accessible to teams building generative AI applications.
- Speculative decoding shifts the inference optimization focus from model size to draft-target model pairing strategy, requiring new operational decisions around model selection and parameter tuning
- Token acceptance rates are critical to performance gains and depend heavily on architectural alignment between draft and target models, making same-family model pairs more practical than cross-architecture combinations
- Hardware utilization improvements from reduced sequential decode steps mean Trainium chips can handle higher throughput on the same infrastructure, directly lowering per-request costs for inference providers
Our Briefing
Weekly signal. No noise. Built for founders, operators, and AI-curious professionals.
No spam. Unsubscribe any time.


