Fintech Cuts Document Review Queue by 60% with Hybrid AI Pipeline
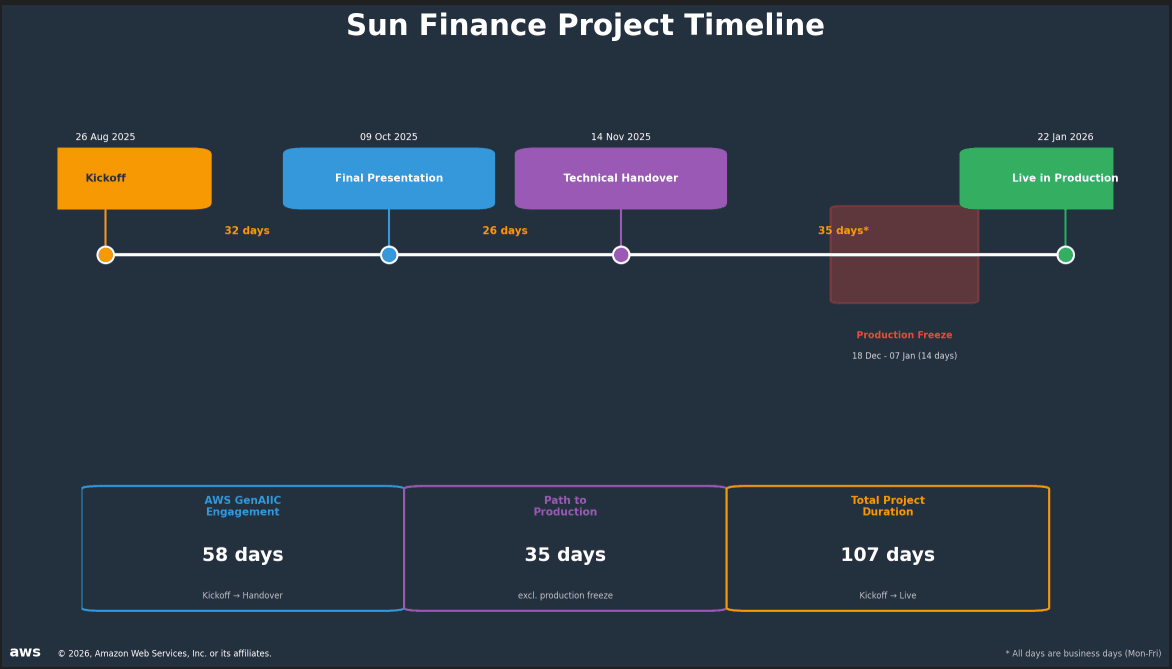
Sun Finance, a Latvian fintech processing 4 million loan evaluations monthly, rebuilt its identity document verification pipeline using Amazon Bedrock, Textract, and Rekognition to handle multilingual documents and multiple ID formats. The system improved extraction accuracy from 79.7% to 90.8%, reduced per-document costs by 91%, and cut processing time from up to 20 hours to under 5 seconds. The company deployed the solution in production within 35 business days of technical handover, reducing manual review requirements from 60% of applications.
Sun Finance, a Latvian fintech processing 4 million loan evaluations monthly, rebuilt its identity document verification pipeline using Amazon Bedrock, Textract, and Rekognition to handle multilingual documents and multiple ID formats. The system improved extraction accuracy from 79.7% to 90.8%, reduced per-document costs by 91%, and cut processing time from up to 20 hours to under 5 seconds. The company deployed the solution in production within 35 business days of technical handover, reducing manual review requirements from 60% of applications.
- Sun Finance combined specialized OCR (Amazon Textract) with LLM-based structuring (Amazon Bedrock) to outperform either tool alone on multilingual identity document extraction
- Extraction accuracy improved from 79.7% to 90.8%, with per-document processing costs cut by 91% and turnaround time reduced from up to 20 hours to under 5 seconds
- The fintech processes 80,000 monthly microloan applications, with 60% previously requiring manual operator review before the AI system went live
- Full project cycle from AWS Generative AI Innovation Center kickoff to production deployment took 107 business days, with the solution live by January 22, 2026
This case demonstrates a practical pattern for combining specialized AI tools with generative models in high-volume document processing workflows. The results show that hybrid approaches (traditional OCR plus LLM refinement) can achieve accuracy gains that neither tool delivers alone, and that serverless architectures on cloud platforms can handle fraud detection at scale without custom infrastructure.
- Hybrid AI pipelines combining specialized OCR with LLM post-processing can solve document extraction problems that single-tool approaches cannot, particularly for multilingual and format-diverse documents
- Serverless cloud architectures with vector similarity search enable fraud detection at scale without requiring custom infrastructure or significant operational overhead
- Fintech companies in developing regions can now process identity documents reliably across multiple languages and ID formats, reducing the manual review bottleneck that has historically limited automation in these markets
Our Briefing
Weekly signal. No noise. Built for founders, operators, and AI-curious professionals.
No spam. Unsubscribe any time.


