Amazon Nova 2 Lite for Content Moderation via Prompting
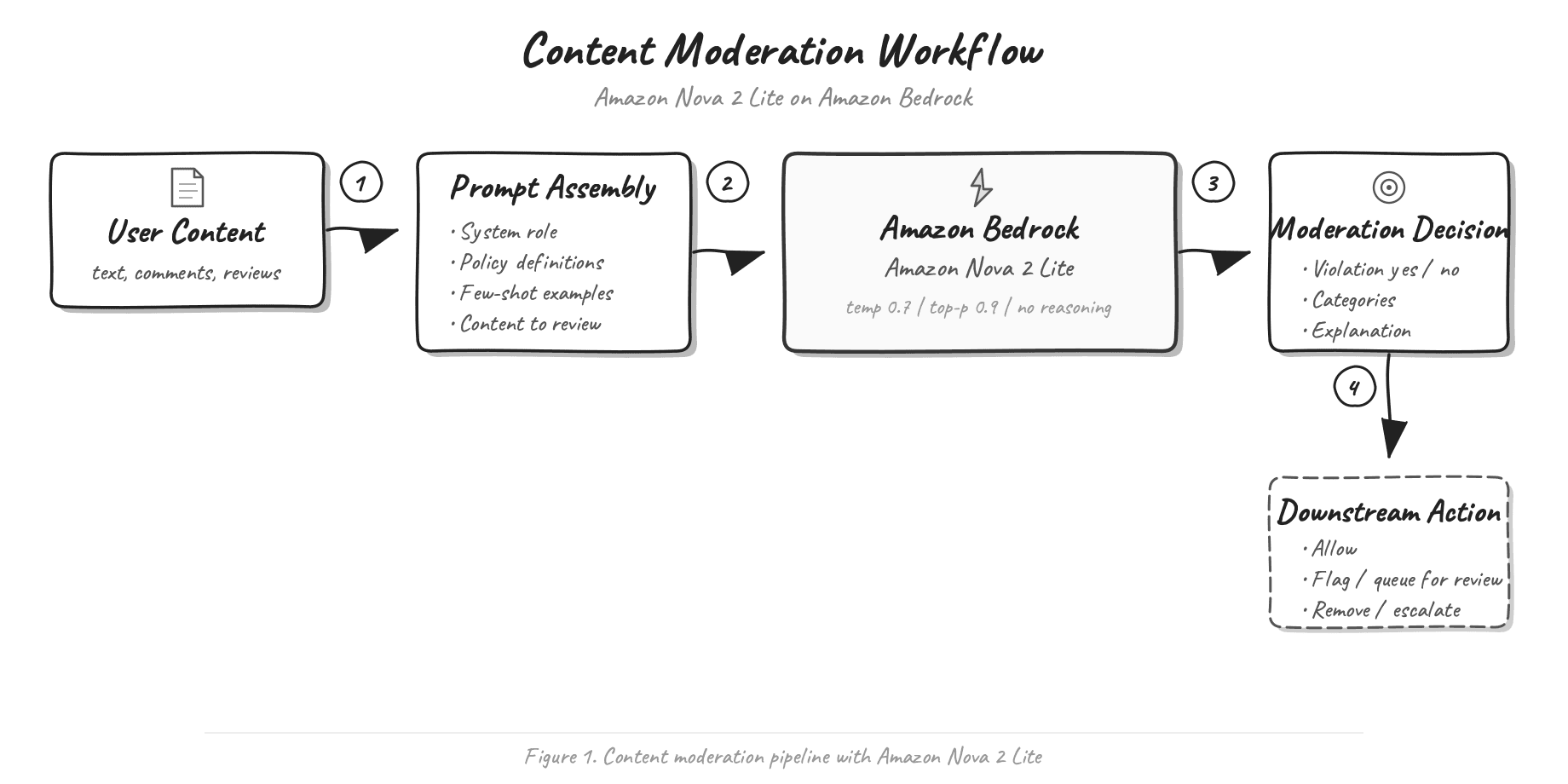
AWS published a guide on using Amazon Nova 2 Lite for content moderation via prompting, demonstrating how to apply the MLCommons AILuminate Assessment Standard's 12-category hazard taxonomy without requiring model fine-tuning. The approach allows organizations to update moderation policies by editing prompts rather than retraining models, and includes benchmarks comparing Nova 2 Lite against other foundation models on public datasets. The technique works with both the AILuminate taxonomy and custom moderation policies, making it adaptable to different organizational needs.
Executive Summary
AWS has published guidance on using Amazon Nova 2 Lite for content moderation through prompt engineering, leveraging the MLCommons AILuminate Assessment Standard's 12-category hazard taxonomy without requiring model fine-tuning. This approach enables organizations to dynamically update moderation policies by modifying prompts rather than retraining models, with published benchmarks demonstrating Nova 2 Lite's performance against competing foundation models on public datasets.
Key Takeaways
- Amazon Nova 2 Lite enables effective content moderation through prompt-based configuration, eliminating the need for computationally expensive model fine-tuning.
- The MLCommons AILuminate Assessment Standard provides a standardized 12-category hazard taxonomy that organizations can adopt or customize for their specific moderation needs.
- Prompt-based moderation allows rapid policy updates without retraining cycles, reducing time-to-deployment for new moderation rules and organizational policy changes.
- Published benchmarks on public datasets enable direct performance comparison between Nova 2 Lite and alternative foundation models, supporting informed model selection decisions.
- The approach is adaptable to both industry-standard taxonomies and custom moderation frameworks, making it applicable across diverse organizational requirements and risk profiles.
Why It Matters
Content moderation at scale is critical for compliance, brand safety, and user trust, yet traditional approaches requiring model retraining are operationally expensive and slow to adapt. This prompt-based method reduces barriers to implementing sophisticated moderation while maintaining flexibility to evolve policies as organizational needs and regulatory requirements change.
Deep Dive
Content moderation has traditionally relied on either manual review (costly and unscalable) or fine-tuned machine learning models (expensive to retrain and slow to update). Amazon Nova 2 Lite addresses this operational challenge by enabling in-context learning through prompt engineering, which allows organizations to define moderation policies declaratively without touching model weights. The approach is grounded in the MLCommons AILuminate Assessment Standard, which provides a structured 12-category hazard taxonomy covering categories such as violence, illegal activities, hate speech, and misinformation. This standardization creates a common language across the industry and allows organizations to benchmark their approaches against peers. The technique supports both adoption of the standard taxonomy and customization for domain-specific or organizational-specific hazards, making it applicable whether an organization operates a general-purpose platform or serves specialized communities with unique moderation requirements. AWS's published benchmarks on public datasets (such as ToxiGen, HateBench, and others) provide concrete performance metrics, enabling practitioners to assess whether Nova 2 Lite meets their precision and recall requirements before deployment. The practical advantage of this approach lies in its operational agility, when a new hazard emerges or regulatory guidance changes, teams can update the moderation prompt in minutes rather than waiting weeks for a retraining pipeline. This also reduces infrastructure costs and ML engineering overhead, allowing smaller teams to implement enterprise-grade content moderation without maintaining large model training operations.
Expert Perspective
From an industry perspective, this represents a maturation of large language model capabilities toward practical operational use cases. Content moderation via prompting aligns with broader industry trends toward post-training customization rather than fine-tuning, reducing the barrier to entry for organizations seeking AI-powered compliance infrastructure. The standardization through MLCommons AILuminate is particularly significant because it enables comparability and reduces the risk of organizational moats around proprietary moderation taxonomies. However, practitioners should remain aware that prompt-based approaches may have lower precision on adversarial or edge-case content compared to fine-tuned models, and the approach requires careful validation against organizational risk tolerances before full-scale deployment.
What to Do Next
- Evaluate your current content moderation approach against the MLCommons AILuminate 12-category taxonomy to identify gaps and overlaps in your existing policy framework.
- Conduct a pilot deployment of Amazon Nova 2 Lite on a representative sample of your moderation workload, measuring precision, recall, and latency against your current solution to establish a performance baseline.
- Develop a prompt library documenting your organization's custom moderation rules and hazard definitions, establishing a version control and testing process for safe policy iteration.
- Assess the cost and operational impact of migrating to prompt-based moderation, including infrastructure consolidation opportunities and potential reductions in model training and fine-tuning spend.
Our Briefing
Weekly signal. No noise. Built for founders, operators, and AI-curious professionals.
No spam. Unsubscribe any time.


