AWS Details Modular Voice Agent Design for Production Scale
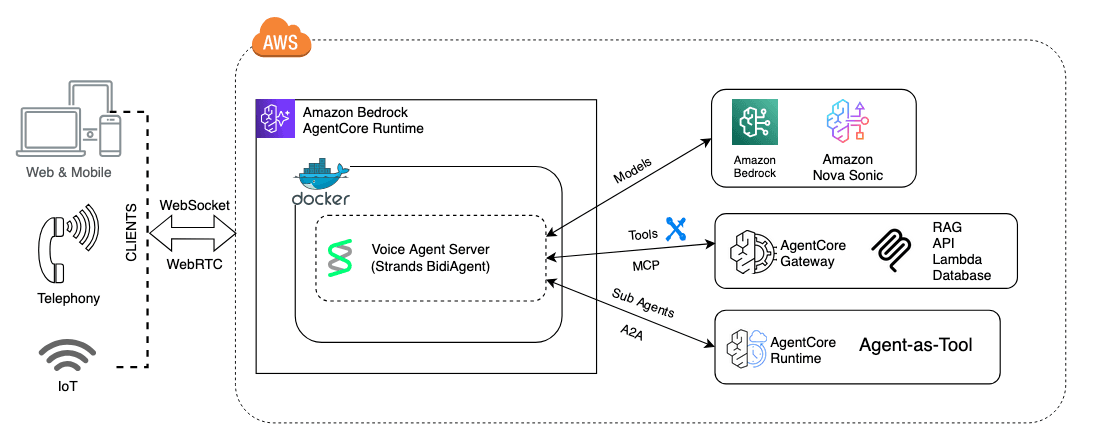
Amazon has published a technical guide on building scalable voice agents using Nova Sonic, a speech-to-speech foundation model, combined with Bedrock AgentCore Runtime and the open source Strands Agents framework. The post outlines three architectural patterns: tool-driven agents, sub-agents acting as tools, and session segmentation strategies that decompose large assistants into specialized, reusable components. The approach addresses common production challenges like latency, real-time audio management, and multi-agent coordination by leveraging serverless hosting, bidirectional WebSocket streaming, microVM-level isolation, and persistent memory across sessions.
Executive Summary
Amazon has published a comprehensive technical guide for building production-scale voice agents using Nova Sonic, a speech-to-speech foundation model, integrated with Bedrock AgentCore Runtime and the open source Strands Agents framework. The guidance outlines three architectural patterns, tool-driven agents, sub-agents as tools, and session segmentation, that address critical production challenges including latency, real-time audio management, and multi-agent coordination through serverless hosting and persistent memory mechanisms.
Key Takeaways
- Three distinct architectural patterns, tool-driven agents, hierarchical sub-agents, and session segmentation, provide modular approaches to decomposing large voice assistants into specialized, reusable components.
- Serverless hosting combined with bidirectional WebSocket streaming and microVM-level isolation enables low-latency, real-time audio processing at production scale.
- Persistent memory across sessions allows voice agents to maintain context and state, improving user experience and reducing redundant processing.
- The integration of Nova Sonic with Bedrock AgentCore Runtime and Strands Agents framework creates a cohesive platform for multi-agent coordination and tool management.
- Session segmentation strategies decompose complex voice interactions into manageable segments, reducing computational overhead and improving system reliability.
Why It Matters
As enterprises increasingly adopt conversational AI for customer engagement, production-grade voice agents require architectural patterns that balance real-time responsiveness with scalability and cost efficiency. This guidance from Amazon provides concrete, framework-agnostic patterns that address the technical bottlenecks that have historically limited voice agent adoption in mission-critical applications.
Deep Dive
Voice agents present unique technical challenges distinct from text-based conversational AI. Real-time audio streaming requires bidirectional communication with strict latency constraints, typically measured in hundreds of milliseconds, where traditional request-response patterns prove insufficient. Amazon's approach using bidirectional WebSocket connections enables continuous audio flow while maintaining agent responsiveness. The three architectural patterns outlined, tool-driven agents, sub-agents as tools, and session segmentation, represent a maturation in how organizations can structure complex voice interactions. Tool-driven agents leverage external APIs and services to extend functionality without increasing model size or latency, allowing agents to perform actions like querying databases or calling third-party services. Sub-agents functioning as tools enable hierarchical decomposition where specialized agents handle specific domains or tasks, improving maintainability and allowing teams to develop and update components independently. Session segmentation further optimizes for production constraints by breaking long interactions into focused segments, each with defined scope and memory, reducing token consumption and processing overhead. The persistent memory mechanism across sessions addresses a critical user experience issue where agents can recall previous interactions and preferences without requiring users to re-establish context. Microvm-level isolation provides security and resource guarantees, ensuring that one agent's behavior does not degrade others in a multi-tenant environment. The use of Bedrock AgentCore Runtime abstracts infrastructure complexity, allowing developers to focus on domain logic rather than distributed systems concerns. This architecture aligns with serverless computing principles where organizations pay only for actual processing time, making voice agents economically viable for variable workloads.
Expert Perspective
The publication reflects the industry shift toward modular, composable AI architectures rather than monolithic models. Leading AI infrastructure teams recognize that production voice systems require not just better models but better operational patterns. By providing prescriptive guidance on tool integration, agent composition, and session management, Amazon acknowledges that model capability represents only one dimension of production readiness. The emphasis on WebSocket streaming and microVM isolation suggests that real-time audio processing requires architectural choices fundamentally different from traditional API-based deployments. Organizations that adopt these patterns early will establish competitive advantages in latency, scalability, and operational cost as voice AI becomes increasingly central to customer experience strategies.
What to Do Next
- Evaluate your current voice agent architecture against the three patterns outlined, tool-driven, hierarchical sub-agent, and session-segmented, to identify which pattern best aligns with your domain requirements and team structure.
- Prototype a WebSocket-based voice agent integration using Nova Sonic and Bedrock AgentCore Runtime to benchmark latency and cost metrics against your current implementation.
- Map your voice agent's existing functionality to discrete tools and sub-agents to identify opportunities for modular decomposition, then document the isolation boundaries and memory requirements for each component.
- Establish a session segmentation strategy for your primary voice interaction flows, defining clear scope, duration, and memory requirements for each segment to optimize for real-time performance and cost efficiency.
Our Briefing
Weekly signal. No noise. Built for founders, operators, and AI-curious professionals.
No spam. Unsubscribe any time.


