Building Production AI Agents: AWS, NVIDIA, Strands Reference Architecture
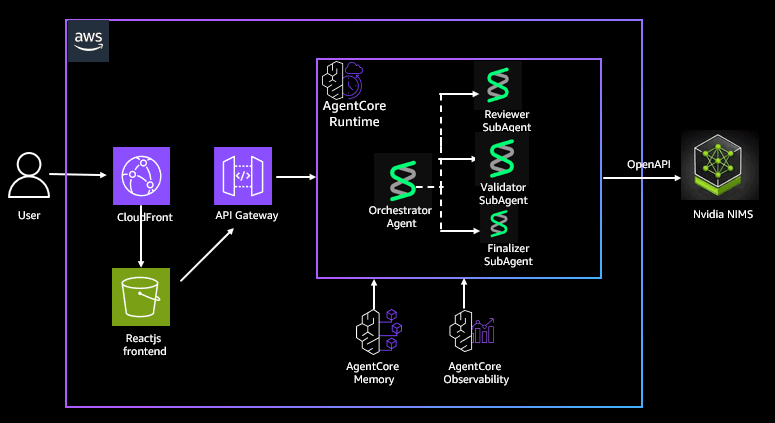
AWS, NVIDIA, and Strands have published a reference architecture for building production-grade multi-agent AI systems that combine GPU-accelerated inference, serverless orchestration, and shared memory. The approach addresses latency, context persistence, and observability challenges that emerge when scaling agent workloads in parallel. The example demonstrates a campaign review system with three specialized agents running concurrently, though the pattern applies to digital assistants and retrieval-augmented generation pipelines.
TL;DR
- Reference architecture combines NVIDIA NIM for GPU inference, Amazon Bedrock AgentCore for managed runtime and shared memory, and Strands Agents for multi-agent orchestration
- Addresses production challenges including inference latency under concurrent load, loss of conversational context in stateless environments, and limited visibility into agent execution
- Demonstrates parallel multi-agent reasoning with a campaign review system featuring persona evaluation, compliance validation, and result aggregation
- Uses hosted NVIDIA NIM APIs with CUDA and TensorRT-LLM optimization to deliver low-latency, high-throughput responses at scale
Why It Matters
Production AI agent systems face distinct challenges that prototype implementations do not encounter: latency degradation under concurrent requests, loss of context between interactions, and operational opacity. This architecture provides concrete patterns for addressing these constraints, making it relevant for organizations moving agent systems from experimental stages to reliable production workloads.
Business Impact
Organizations deploying AI agents for automation, customer service, and decision support need systems that respond in near real-time, maintain context across interactions, and operate without constant infrastructure management. This reference architecture reduces the engineering burden of building such systems by integrating managed services and demonstrating proven patterns for parallel agent execution and result aggregation.
Key Implications
- GPU-accelerated inference via managed APIs becomes a practical baseline for production agent systems rather than an optimization reserved for high-volume deployments
- Shared memory and observability built into the orchestration layer address operational challenges that typically require custom instrumentation
- Multi-agent parallelization with context persistence enables more complex reasoning workflows than single-agent systems can support
What to Watch
Monitor adoption patterns to understand whether this integrated approach becomes standard practice for production agent deployments or remains specialized to specific use cases. Watch for performance benchmarks comparing this architecture to alternative approaches, and track how organizations handle cost optimization as agent workloads scale.
Our Briefing
Weekly signal. No noise. Built for founders, operators, and AI-curious professionals.
No spam. Unsubscribe any time.