Bedrock AgentCore adds versioned datasets for stable agent evaluation
Amazon Bedrock AgentCore now supports versioned dataset management for agent evaluation, allowing teams to maintain stable test baselines alongside production traffic. The feature lets developers author test cases with expected outputs and assertions, then publish immutable versions that serve as regression gates in CI/CD pipelines. This addresses a core problem in agent testing: non-deterministic outputs make it impossible to know whether score changes reflect actual improvements or just sampling variance.
TL;DR
- Versioned datasets in Bedrock AgentCore lock test cases as immutable checkpoints while allowing mutable drafts for iteration
- Ground truth assertions (expected outputs, tool sequences, PII checks) distinguish actual correctness from subjective LLM scoring
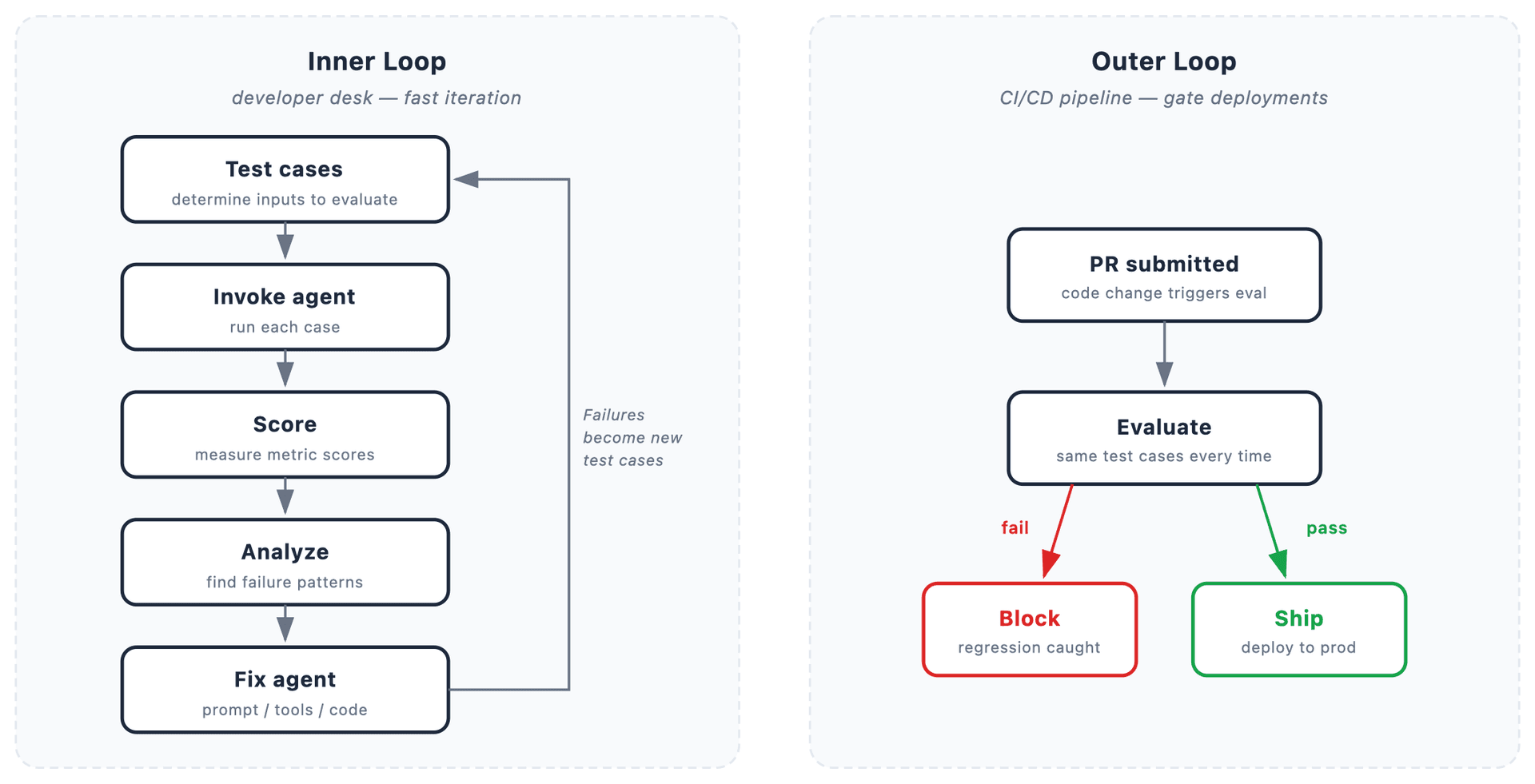
- Same locked dataset powers both developer inner loops (minutes-scale iteration) and outer loops (CI/CD regression gates)
- Production failures automatically become permanent test cases that all future changes must pass
Why It Matters
Agent evaluation is fundamentally broken without stable inputs and ground truth. Because LLMs are non-deterministic, the same input produces different outputs across runs, making single evaluation scores meaningless. Without versioned datasets, teams cannot distinguish real improvements from sampling noise or catch regressions before production.
Business Impact
Organizations deploying agents to production need reliable gates that actually catch breaking changes. Versioned datasets eliminate false confidence from passing evaluations that only pass because test inputs shifted, reducing the risk of shipping broken agents and the cost of debugging production failures.
Key Implications
- Evaluation rigor moves from ad-hoc test cases to disciplined, versioned baselines that persist across sprints and teams
- Production incidents become permanent test fixtures, forcing all future changes to handle previously discovered failure modes
- CI/CD pipelines gain meaningful regression detection instead of testing against whatever inputs happened to be nearby
What to Watch
Monitor whether teams actually adopt versioned datasets as a discipline or treat them as optional overhead. Watch for patterns in how production failures get captured and whether they accumulate into comprehensive test suites or remain scattered. Track whether this pattern spreads to other LLM evaluation frameworks beyond Bedrock.
Our Briefing
Weekly signal. No noise. Built for founders, operators, and AI-curious professionals.
No spam. Unsubscribe any time.